
CVPR16 Highlights @ Caesar Palace, Vegas














This year CVPR saw a staggering attendance of over 3600
participants. As I sat in one of those chandelier lit colossal
ballrooms of Caesar Palace (checkout some cool photos from my Vegas trip
above :smiley: ), I had only one aim in mind - to
keep an eye for honest research which is of some interest to
me. Needless to say publications featuring CNNs and RNNs were in
abundance. However it seems like the vision community as a whole has
matured a little in dealing with these obscure
learning machines and the earlier fascination with the tool itself has
been replaced by growing interest in its creative and meaningful
usage. In this post I will highlight some of the papers that seem to
be interesting based on a quick glance. This blog post is very similar
in spirit to the excellent posts by Tomasz
Malisiewicz
where he highlights a few papers from every conference he visits. I
think it is a good exercise for anyone to keep up with the breadth and
depth of a fast moving field like Computer Vision. As always many a
grad students (including me) and possibly other researchers are
waiting for Tomasz’ highlight of CVPR 2016 (which based on his recent
tweet is
tentatively named ‘How deep is CVPR 2016?’). But while we are
waiting for it let us dive in!
Vision and Language
One of the major attractions for me were the oral and spotlight sessions on Vision and Language and the VQA workshop. There were some good papers from Trevor Darrell’s group in UC Berkeley -
-
Neural Module Network: This work proposes composing neural networks for VQA from smaller modules each of which performs a specific task. The architecture of the network comes from a parse of the question which specifies the sequence in the which operations need to be performed on the image to answer the question. A follow up work is also available here where instead of committing to a single network layout, multiple layouts are proposed and a ranking is learned using the REINFORCE rule in a policy gradient framework.
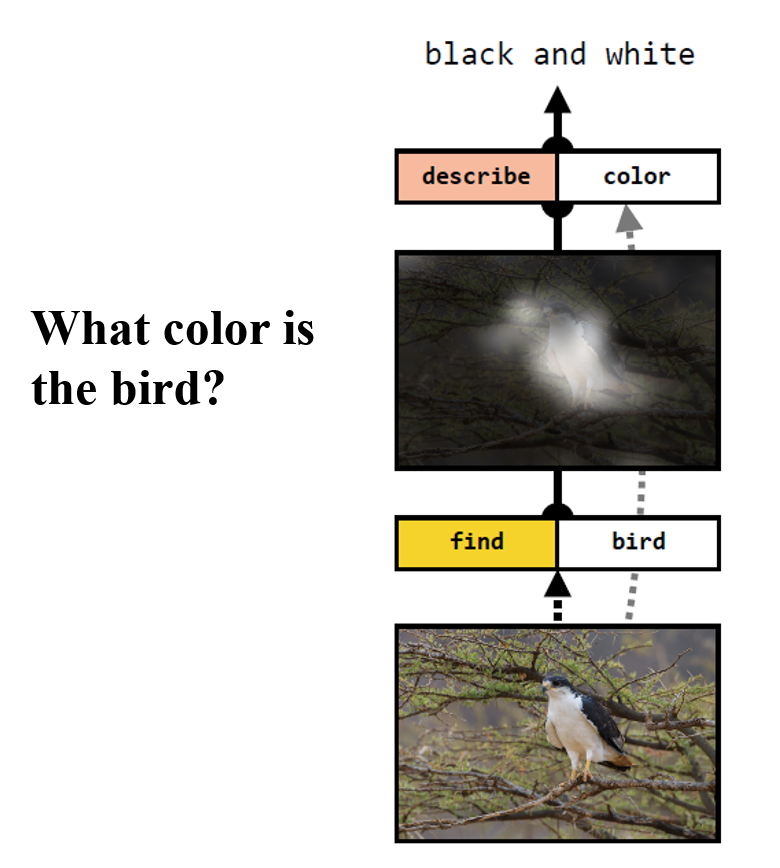
-
Deep Compositional Captioning: Describing Novel Object Categories without Paired Training Data: Most image captioning models required paired image-caption data to train and cannot generate captions describing novel object categories that aren’t mentioned in any of the captions in the paired data. The main contribution of the paper is to propose a method to transfer knowledge of novel object categories from object classification datasets.
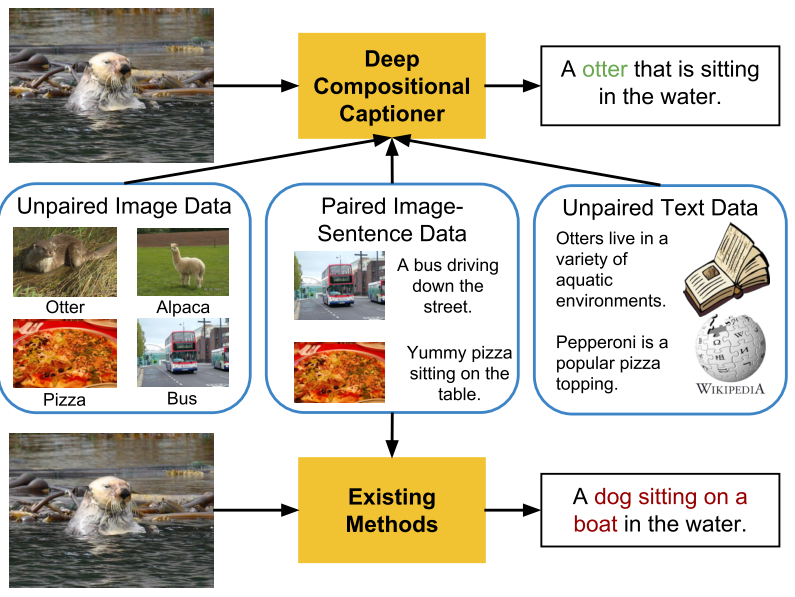
-
Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding: Most deep learning approaches to tasks involving image and language require combining the features from two modalities. The paper proposes MCB as an alternative to simple concatenation/addition/elementwise multiplication of the image and language features. MCB is essentially an efficient way of performing an outer product between two vectors and so results in a straightforward feature space expansion.
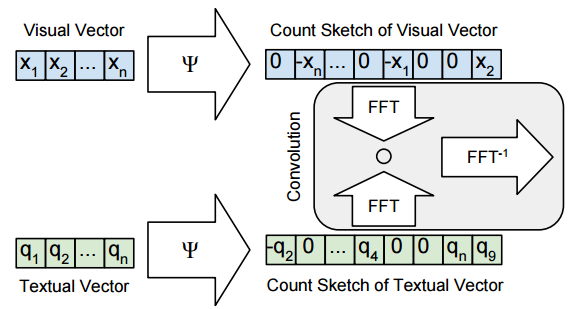
There was also this work born out of a collaboration between Google, UCLA, Oxford and John Hopkins that deals with referring expressions which are expressions used to uniquely identify an object or a region in an image -
-
Generation and Comprehension of Unambiguous Object Descriptions: The main idea of the paper is to jointly model generation and interpretation of referring expressions. A smart thing about this is that unlike independent image caption generation which is hard to evaluate, this joint model can be evaluated using simple pixel distance to the object being referred to.
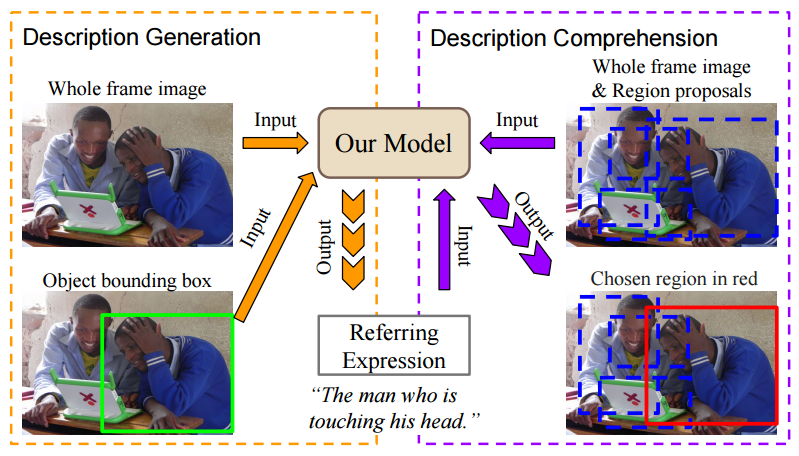
Shifting the attention from caption generation to use of captions as training data for zero-shot learning, researchers from University of Michigan and Max-Planck Institute introduced a new task and dataset in -
-
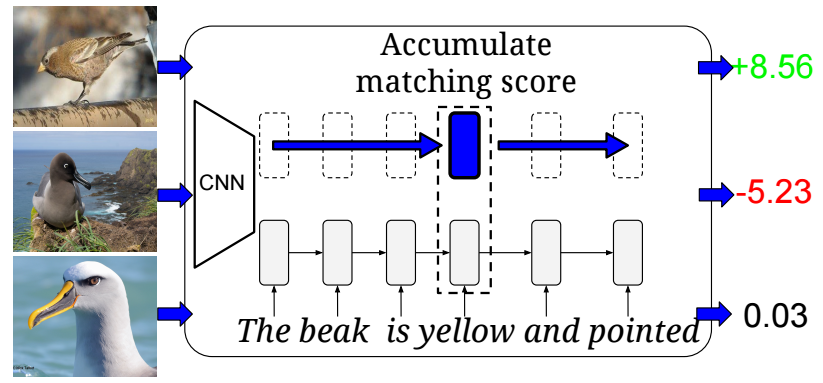
Learning Deep Representations of Fine-Grained Visual Descriptions: The task is to learn to classify novel categories of birds given exemplar captions that describe them and paired image caption data for other bird categories. The proposed model learns to score captions and images and classifies any new bird image as belonging to the category of the nearest neighbor caption.
During the VQA workshop Jitendra Malik brought something unexpected to the table by pointing out that vision and language while being the most researched pillars of AI aren’t the only ones. There is a third pillar which has to do with embodied cognition, the idea that an agent’s cognitive processing is deeply dependent in a causal way on the characteristics of the agent’s physical, beyond-the-brain body. He argued that in order for a robot to ingrain the intuitive concepts of physics which allow humans to interact with the environment on a daily basis, the robot needs to be able to interact with the world and see the effect of its actions. This theme reflects in some of the recent research efforts lead by his student Pulkit Agrawal at UC Berkeley -
-
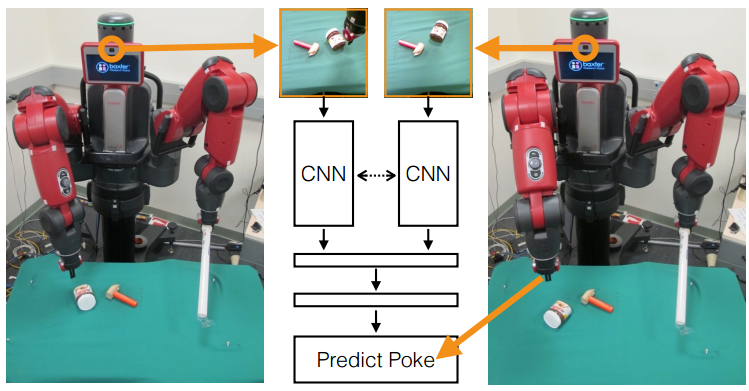
Learning to Poke by Poking: Experiential Learning of Intuitive Physics: The main idea here is to let a robot run amok in the world and learn to perform specific actions in the process. In this case the robot repeatedly pokes different objects and records the images before and after the interaction collecting 400hrs of training data. Next a network is trained to produce the action parameters given the initial and final image. In this way the robot learns certain rules of physics like the relation between force, mass, acceleration and other factors that affect the change like friction due to a particular surface texture. At test time, this allows the robot to predict an action that will produce a desired effect (in this case specified by initial and final images). Also refer to their previous work Learning to See by Moving where egomotion is used as supervision for feature learning.
Some other invited speakers at VQA workshop were - Ali Farhadi, Mario Fritz, Margaret Mitchell, Alex Berg, Kevin Murphy and Yuandong Tian. Do checkout their websites for their latest works on Vision and Language.
Object Detection
Collaborations between FAIR, CMU and AI2 brought us some interesting advances in object detection -
-
Training Region-Based Object Detectors with Online Hard Example Mining: This work is a reformulation of the classic hard negative mining framework that was once popular for training object detectors with far more negative/background samples than positive examples. The training involved beginning with an active and possibly balanced set of positives and negatives. A classifier trained on this active set was applied to the complete training set to identify hard false positives which were then added to the active set and the process was repeated. This paper presents an online version of this methodology which rhymes well with current object detectors like Fast-RCNN which are trained using SGD with mini-batches.
-
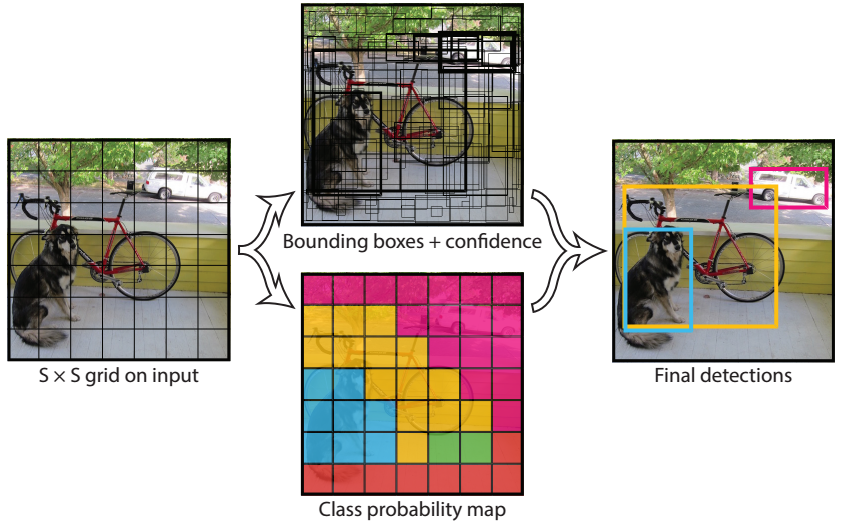
You Only Look Once: Unified, Real-Time Object Detection: A little pony used its magical powers to create a really fast and simple object detector. The key idea is to use a single forward pass through a convolutional network and produce a fixed number of bounding box proposals with corresponding confidence values, and class probabilities for every cell on a grid. The pony also took great risk but delivered a mind blowing live demo of YOLO Object Detector during its oral session at CVPR.
Folks from ParisTech also presented their work on improving localization of object detectors -
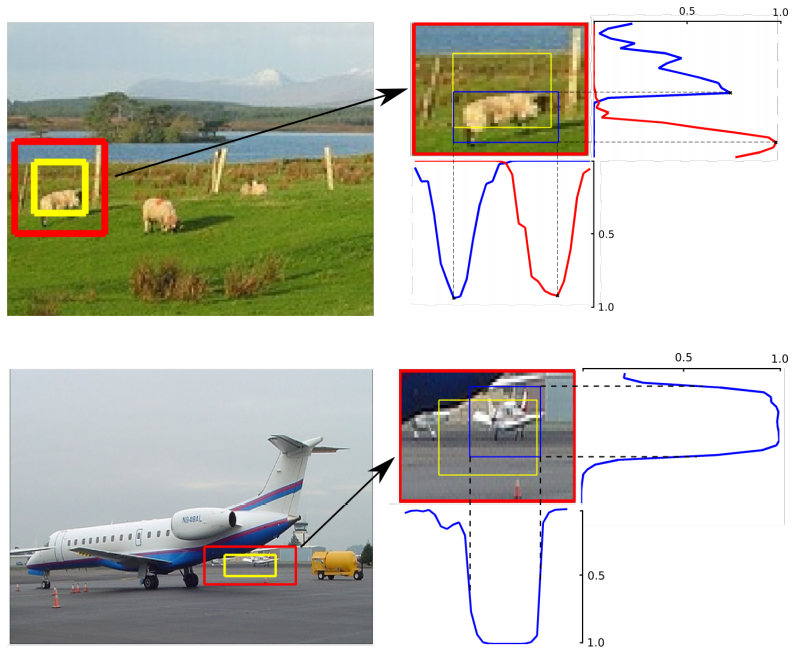
- LocNet: Improving Localization Accuracy for Object Detection: This work proposes an approach to improve object localization. First the initial bounding box is enlarged. Then a network is used to predict for each row/column the probability of it belonging inside the bounding box (or alternatively the probability of that row/column being an edge of the final bounding box).
Recognition and Parsing in 3D
Object detection in 3D seems to be gradually catching up with its 2D counterpart -
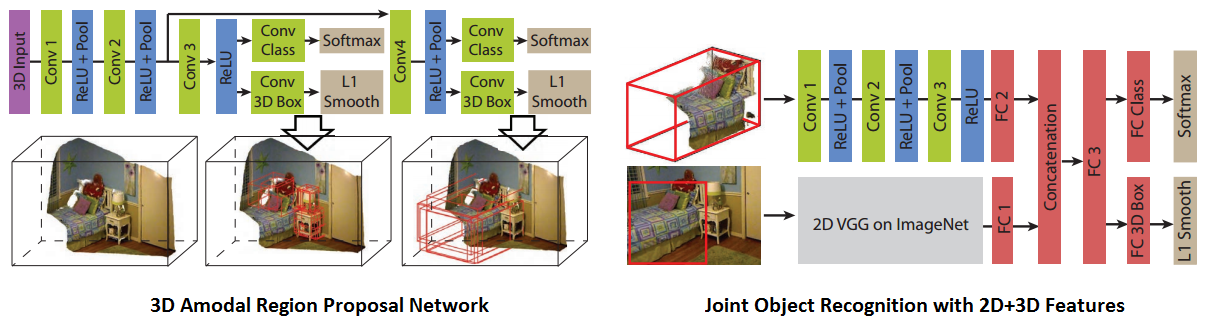
- Deep Sliding Shapes for Amodal 3D Object Detection in RGB-D Images: This paper from Jianxiong Xiao’s group in Princeton shows how to extend the Region Proposal Network (RPN) from Faster-RCNN to do 3D region proposal. This region proposal is amodal meaning that the proposed bounding box includes the entire object in 3D volume irrespective of truncation or occlusion. For recognition they combine deep learned 2D appearance features from image with 3D geometric features from depth extracted using 2D/3D ConvNets respectively.
- 3D Semantic Parsing of Large-Scale Indoor Spaces: This paper due to a collaboration between Stanford, Cornell and University of Cambridge deals with parsing of large scale 3D scenes. For instance consider parsing an entire building into individual rooms and hallways, and then further identifying different components of each room such as walls, floor, ceiling, doors, furnitures etc. The paper also suggests novel applications that can result from this kind of parsing - generating building statistics, analysing workspace efficiency, and manipulation of space such as removing a wall partition between two adjacent rooms.

- GOGMA: Globally-Optimal Gaussian Mixture Alignment: Gaussian mixture alignment can be used for aligning point clouds where both the source and target point clouds are first parameterized by a GMM. The alignment is then posed as minimizing a discrepancy measure between the 2 GMMs. This paper presents a globally optimal solution when the discrepancy measure used is L2 distance between the densities.

Weakly Supervised and Unsupervised Learning
With availability of good deep learning frameworks like Tensorflow, Caffe etc, supervised learning in many cases is a no-brainer given the data. But collecting and curating data is a huge challenge in itself. There are even startups like Spare5 (they also had a booth at CVPR) which provide data annotation as a service. Nonetheless sometimes collecting data is not even an option. Say for example the task of finding dense correspondence between images. A dataset for this task would have a huge impact on other tasks like optical flow computation or depth estimation. However we are yet to see any dataset for this purpose. The following paper has an interesting take on solving this problem in an unsupervised fashion
- Learning Dense Correspondence via 3D-guided Cycle Consistency: The idea in this paper is to match both source and target real images with images rendered from a synthetic mesh. This establishes a consistency cycle where the correspondence between the matched synthetic images is known from the rendering engine by construction. This is used as a supervisory signal for training a ConvNet that produces a flow field given source and target images.
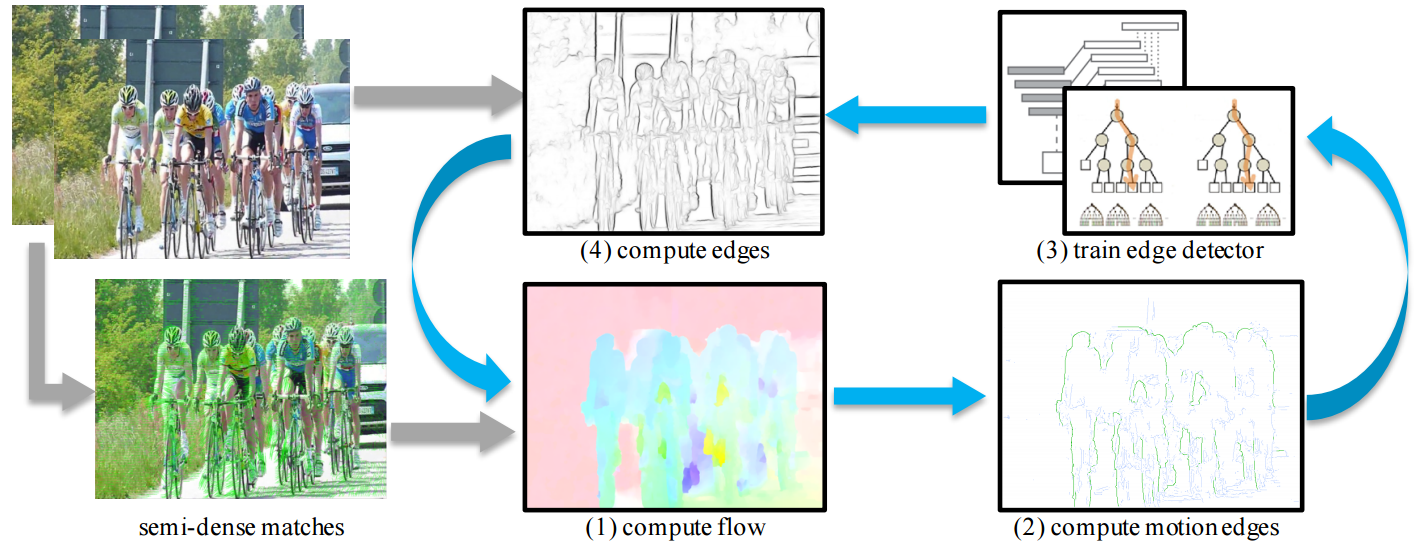
It wouldn’t be wrong to say - Piotr Dollar is to Edge Detection what Ross Girshick is to Object Detection. In this next paper Piotr and collaborators from Georgia Tech introduce an unsupervised method for edge detection -
- Unsupervised Learning of Edges: The key insight is that motion discontinuities always correspond to edges even though the relation does not hold in the other direction. Their algorithm alternates between computing optical flow and using it to train their edge detector. The output of the improved detector is then further used to improve the optical flow and the process continues. Over time both optical flow and edge detection benefit from each other.
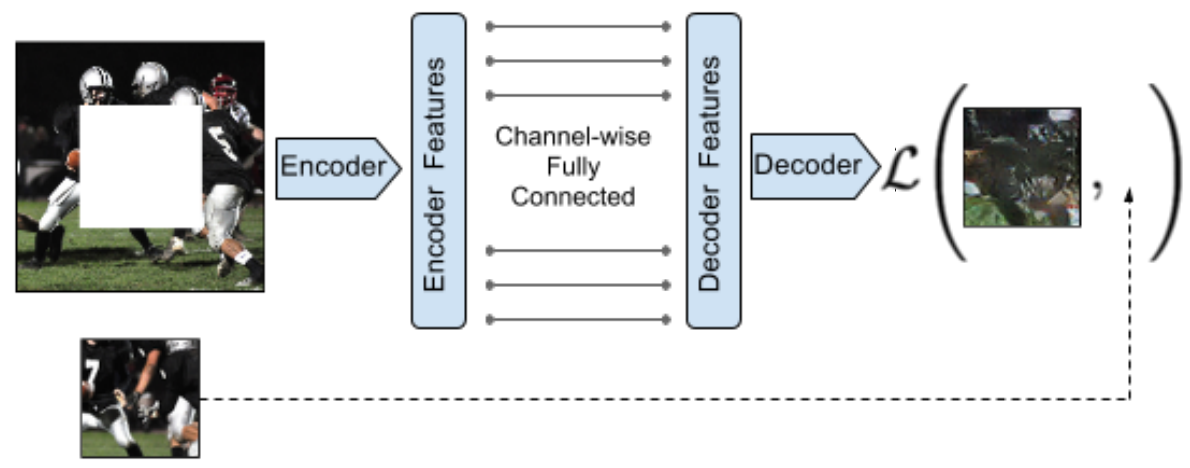
Denoising Autoencoders have been used before for unsupervised feature learning. However depending on the noise characteristics the encoder may not need to capture the semantics and often the clean output can be produced from low level features. The next paper shows how to use an encoder-decoder framework to do unsupervised feature learning in a way that forces features to capture higher level semantics and as a byproduct produces reasonable inpainting results -
- Context Encoders: Feature Learning by Inpainting: Given an image with a region cropped out from it, the encoder produces a feature representation. These features are passed on to a decoder that produces the missing region. One of their results is that pretraining a recognition network in this fashion achieves better performance than random initialization of weights.
The next couple papers are about weakly supervised learning where annotation is available though not in the most direct form.
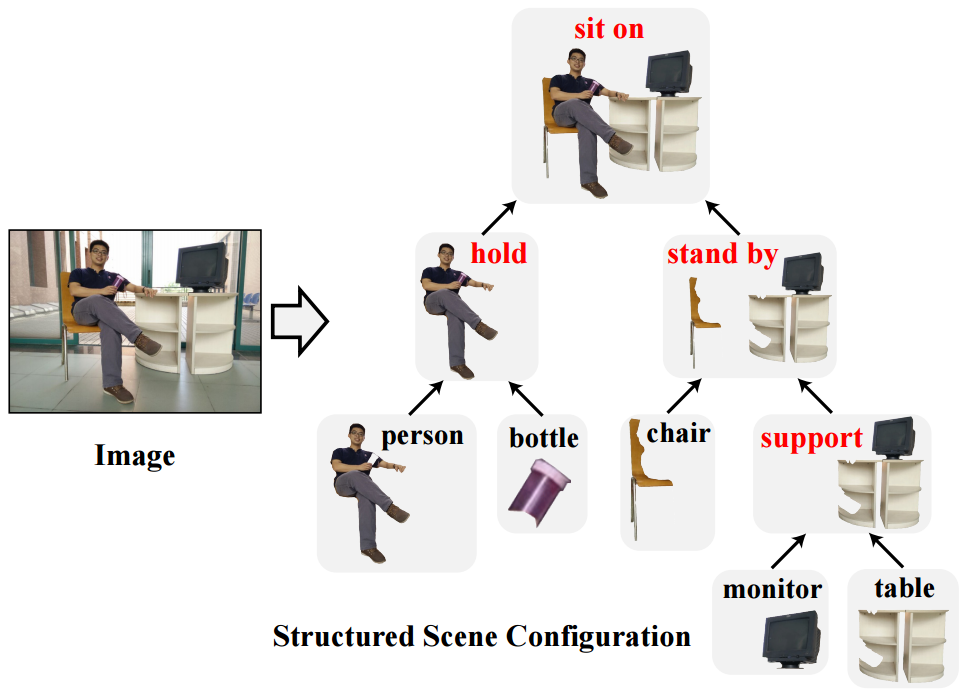
- Deep Structured Scene Parsing by Learning with Image Descriptions: The paper proposes a method for hierarchically parsing an image using sentence descriptions. For example given a sentence - A man holding a red bottle sits on the chair standing by a monitor on the table, the task is to parse the scene into something like
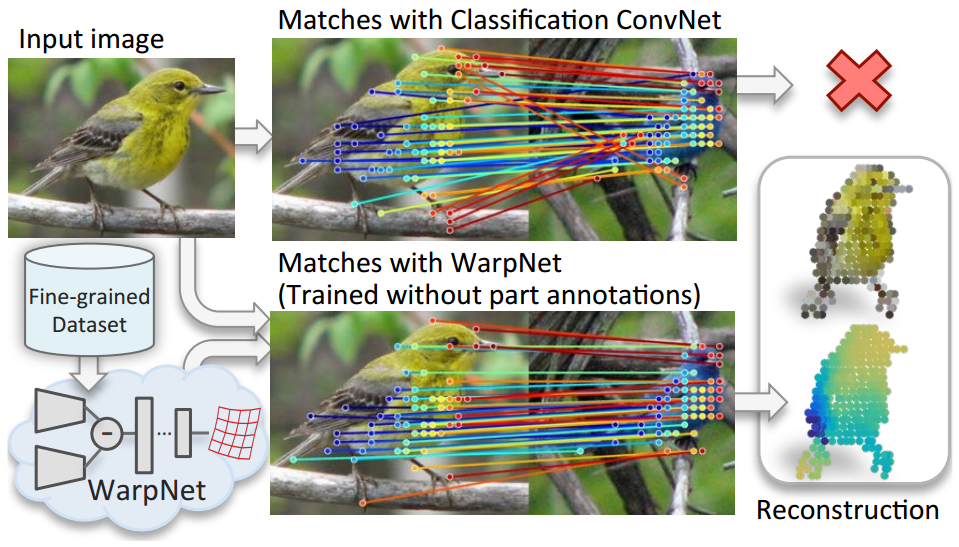
- WarpNet: Weakly Supervised Matching for Single-view Reconstruction: Consider the problem of reconstructing a bird from a single image. One way to do this is to use a fine grained birds dataset and use key-point matches across instances to do non-rigid structure from motion. However traditional key-point detectors like SIFT would fail to give good correspondence due to appearance variations. This paper proposes WarpNet, a network that produces a Thin Plate Splines warping that is used as a shape prior for achieving robust matches. Furthermore the network is trained in an unsupervised manner without any part annotations.
Semantic Segmentation
FCNs and Hypercolumn have been the dominant approaches for semantic segmentation since CVPR 2015. But it is not trivial to adapt these to instance segmentation which is the goal of the next paper-
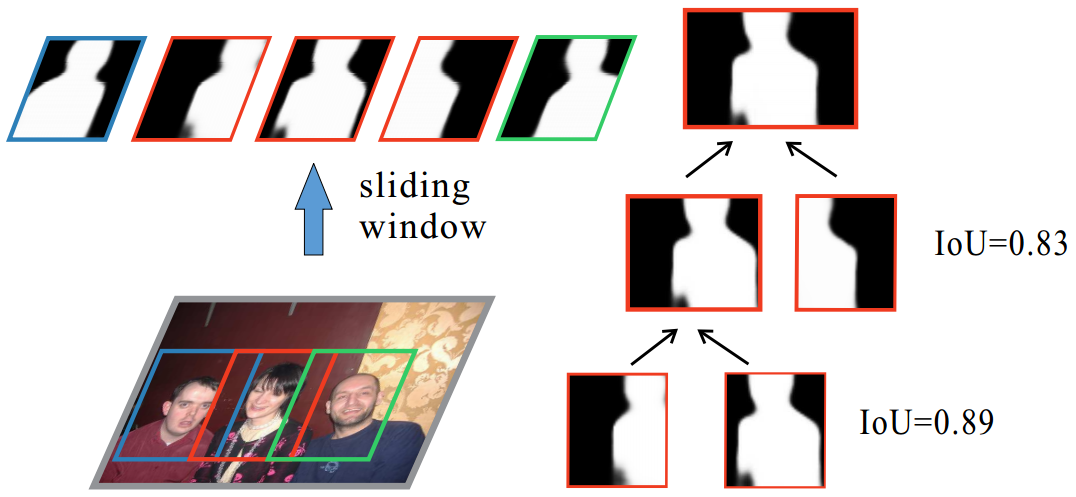
- Multi-scale Patch Aggregation for Simultaneous Detection and Segmentation: The proposed approach is to densely sample predefined regions in the image and for each region produce a segmentation mask (basically foreground/background segmentation) and a classification. The segmentation masks are then fused together to get instance level segmentation.
In a previous work from Vladlen Koltun’s group, inference over fully connected CRFs was proposed as an effective and efficient (using filtering in a high dimensional space with permutohedral lattice) way to do semantic segmentation. The following is an extension of that work to semantic segmentation in videos -
- Feature Space Optimization for Semantic Video Segmentation: For semantic segmentation in still images the fully connected CRFs could operate in a very simple feature space - RGB color channels and pixel coordinates. An obvious extension to video using time as an extra feature does not work since moving objects take apart pixels belonging to the same object in consecutive frames. The proposed approach learns an optimal feature space over which fully connected CRFs with gaussian edge potentials can be applied as before.

The following paper from UCLA and Google proposes an alternative to using fully connected CRFs -
- Semantic Image Segmentation with Task-Specific Edge Detection Using CNNs and a Discriminatively Trained Domain Transform: In this work, features produced by a ConvNet are used to produce both a semantic segmentation mask as well as an edge map. The produced edge map is then used to perform domain transform on the segmentation mask for edge preserving filtering. The entire system is trained end-to-end.
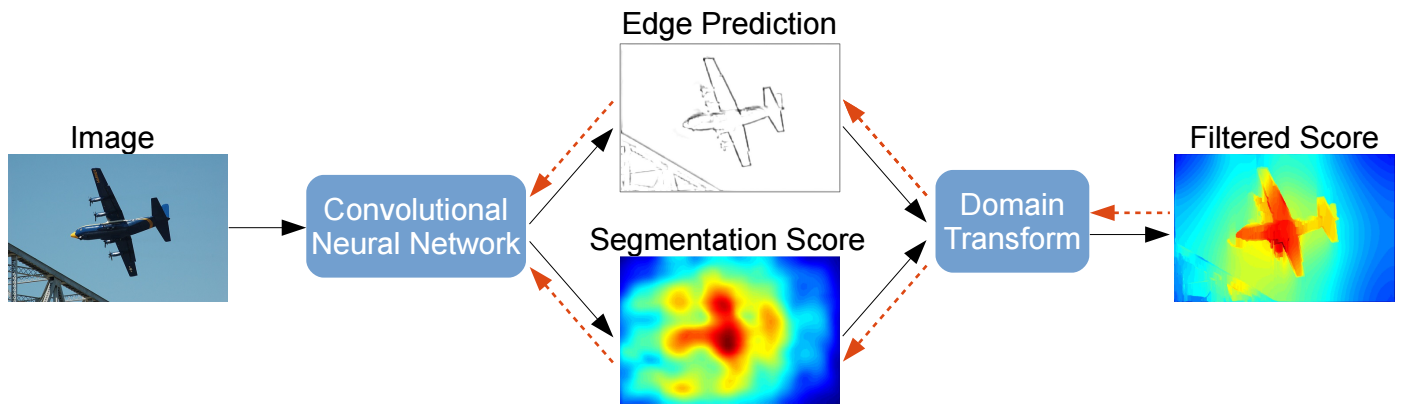
Image Captioning
Andrej Karpathy has been a pioneer in image caption generation technology (even though it is far from being perfect yet). In the following paper he and Justin Johnson from Fei Fei Li’s group in Stanford extend their captioning algorithm to generate captions densely on an image -
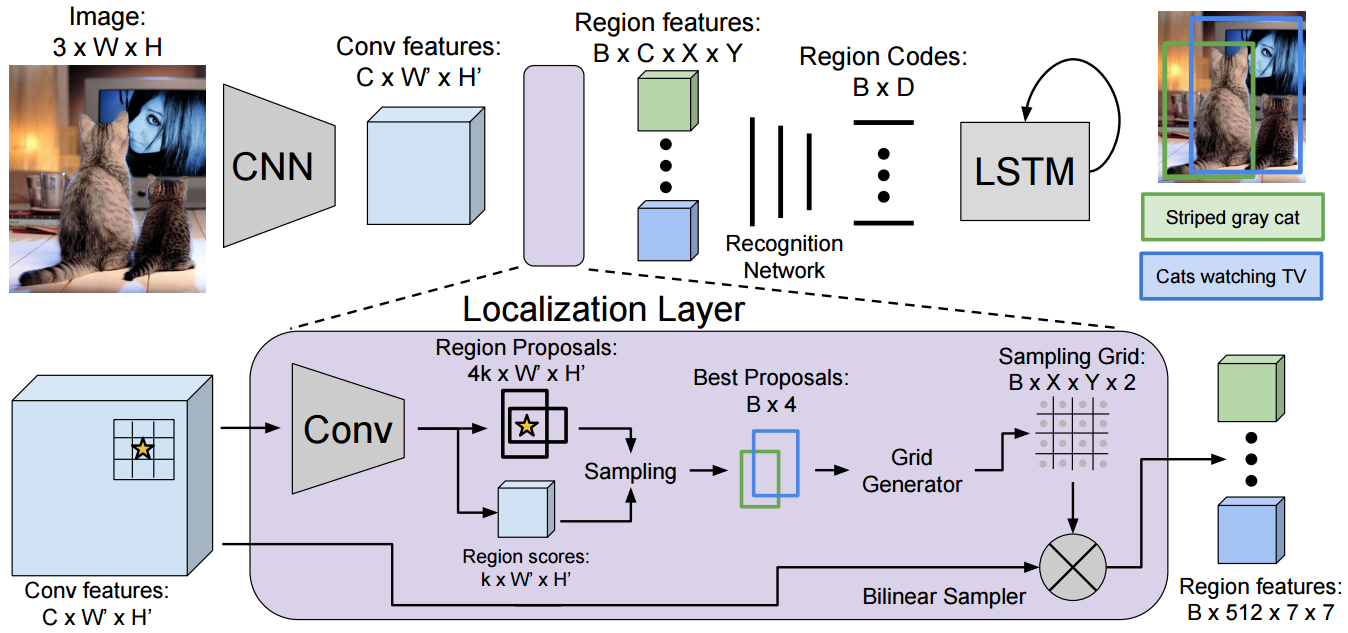
- DenseCap: Fully Convolutional Localization Networks for Dense Captioning: An image is fed into a network that produces convolutional feature maps. A novel localization layer then takes this feature maps and produces region proposals. Bilinear interpolation is used to get region features from the full size feature maps which are fed into another network with RNN at the end that generates a description for that region.
Stereo and Monocular Vision
The following paper from Noah Snavely and team from Google shows us how to generate high quality images from deep nets -
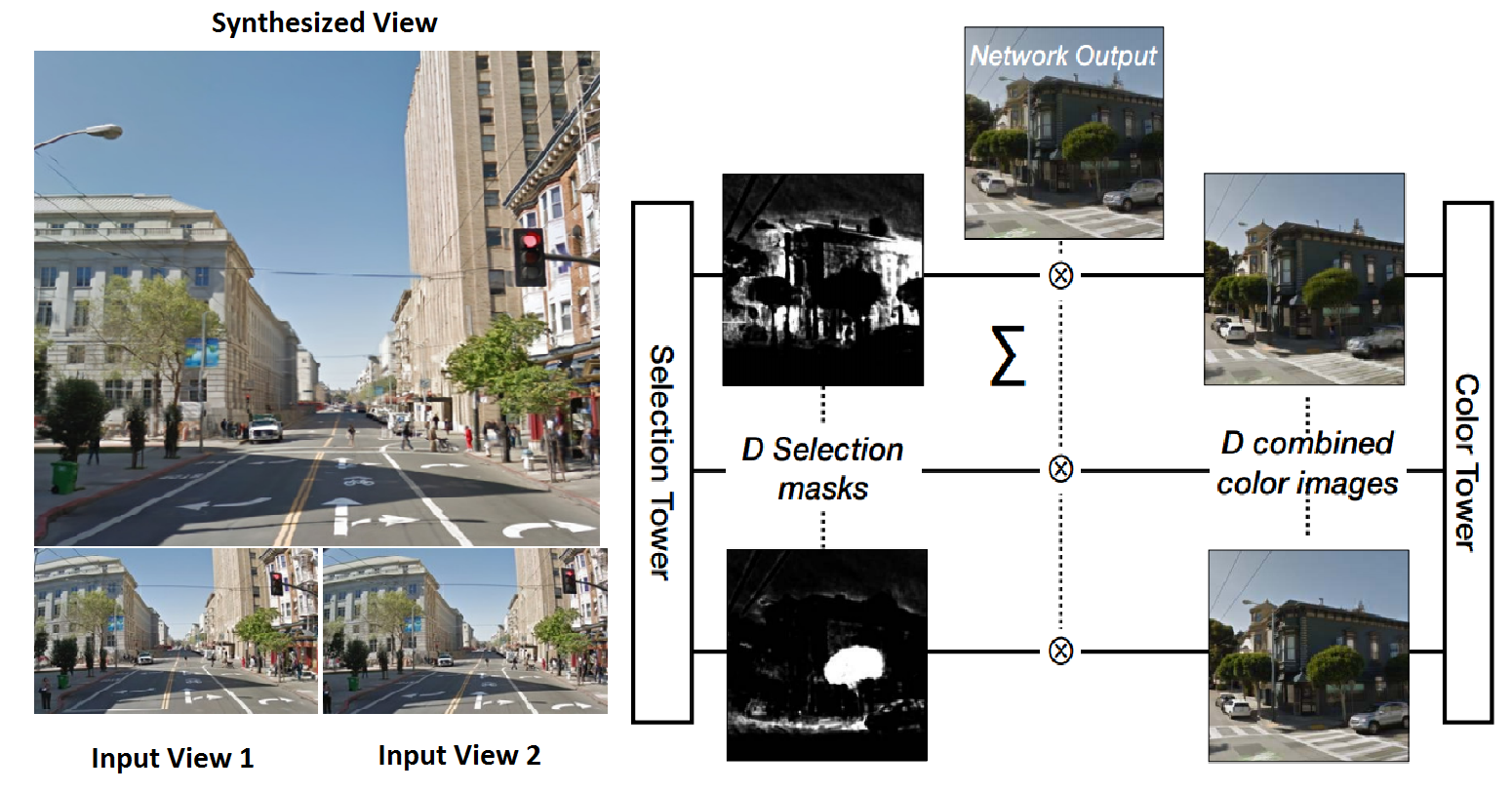
- Deep Stereo: Learning to predict new views from world’s imagery: The task is that of novel view synthesis from a given pair of images from different views. A plane sweep volume is feed into a network with a carefully designed architecture that consists of a Color Tower which learns to warp pixels and a Selection Tower which learns to select pixels from the warped image produced by the _Color Tower.
Current stereo depth estimation algorithms work very well for images of static scenes with sufficient baseline. However, depth estimation in low baseline conditions where the foreground and background move relative to each other is still a hard problem. The next paper from Vladlen Koltun’s group talks about dense depth estimation of scenes with moving objects from consecutive frames captured using a monocular camera.
- Dense Monocular Depth Estimation in Complex Dynamic Scenes: Due to moving objects present in the scene, the optical flow field is first segmented. Depth is estimated using separate epipolar geometry of each segment while enforcing the condition that each segment is connected to the scene.
